
Overheard at CVPR 2026: research, robotics, China, benchmarks, networking

“Hi there, are you going to CVPR this year? Could I pay you to do me a favor?”
“Yes?”
“I am a student in China and the author of an accepted paper. I won’t be able to get a visa to go to Denver. Could you put up my poster for me and take a photo of it?”
A message from a stranger arrived in my RedNote inbox a few days before I left for this year’s CVPR, the top conference in computer vision and one of the most influential gatherings in AI. The acceptance was a milestone in this student’s academic career - his first paper at a major international conference. He was heartbroken that he would not be there to stand beside it. I told him to keep his money. I’d be happy to help.
What follows are some honest, unpolished thoughts from my week in Denver, organized loosely by theme.
Research: the 3D debate isn’t what you think it is

( illustration from What Is (and What Is Not) a Good Use of AI in Journalism? by Juliana Castro Varón)
The intellectual debate everyone was having came to a head at the Bitter Lessons workshop, where Vincent Sitzmann (MIT) and Jon Barron (Google DeepMind) gave back-to-back talks on whether explicit 3D representations still have a future in computer vision research. Both have already conceded enormous territory to the bitter lesson, the old observation by Rich Sutton that general methods riding on scale keep beating clever hand-crafted ones. 大力出奇迹, as how the Chinese research community describes it: brute force works miracles. Sitzmann’s position, laid out in his blog post “The flavor of the bitter lesson for computer vision,” argues that we scoped vision tasks like segmentation and 3D reconstruction because they were solvable — but the goal was always intelligence. He believes that end-to-end world models will eventually skip human-designed intermediate steps including 3D.
Barron’s rebuttal offered a scorecard instead, walking through one application at a time and asking what the final deliverable actually is. For robotics, explicit 3D isn’t needed when the deliverable is actions. The same goes for video generation, where the output is finished pixels and nobody minds if generating them is slow and expensive. By contrast, the calculus flips for interactive media: games, AR/VR, and live broadcasts can’t tolerate slow, costly pixels — especially while generative AI remains bottlenecked by the physics of compute. His strongest case was engineering, manufacturing, and construction, a fifth of the global economy, where the deliverable simply is the 3D model. As he put it: “You cannot live inside a video of a house!”

( image from @jon_barron)
So the two supposed opponents actually agree: 3D is obsolete for robotics. The live disagreement covers only Barron’s last two cases, interactive media and physical manufacturing. And Sitzmann’s blog goes after exactly those, arguing that a 3D printer is ultimately just another robot. The debate has since spilled beyond the conference: a counter-blog from Brown’s IVL lab argues that 3D isn’t a hand-crafted bias at all, but a measurable property of the physical universe. So the question at CVPR 2026 was never whether 3D is dying, but really, how much of the map it still holds.
The other phrase you couldn’t escape in the hallways: world models. Everything is a world model now. Which brings me to —
Robotics: vision became embodied AI

( image from the Bittersweet Lessons of Recognition by Georgia Gkioxari)
The ultimate test of vision is intelligence, which is why robotics, embodied vision, and world models dominated this year’s conversation. The honest caveat, which even the world-model optimists admit: the bottleneck is paired perception-action data at scale. If a robot has never seen a river before, would it know how to cross it?
But this is also where the most optimistic idea of the conference lives. Georgia Gkioxari’s workshop talk reframed the bitter lesson as a bittersweet one: every time a layer of technology matures, it stops being the frontier and becomes the foundation for the next batch of barely-working problems. The field spent decades grinding the same ten problems because nothing worked. Now that core vision largely does, the horizon has exploded. If you’re a student feeling discouraged: this is the best time to start, and not all of it requires a gazillion GPUs.
China: present in the papers, absent from the halls
( image from @CVPR)
The China story of this conference is really one about the two doors at a top US AI conference: one is being opened for talent while geopolitics closes another.
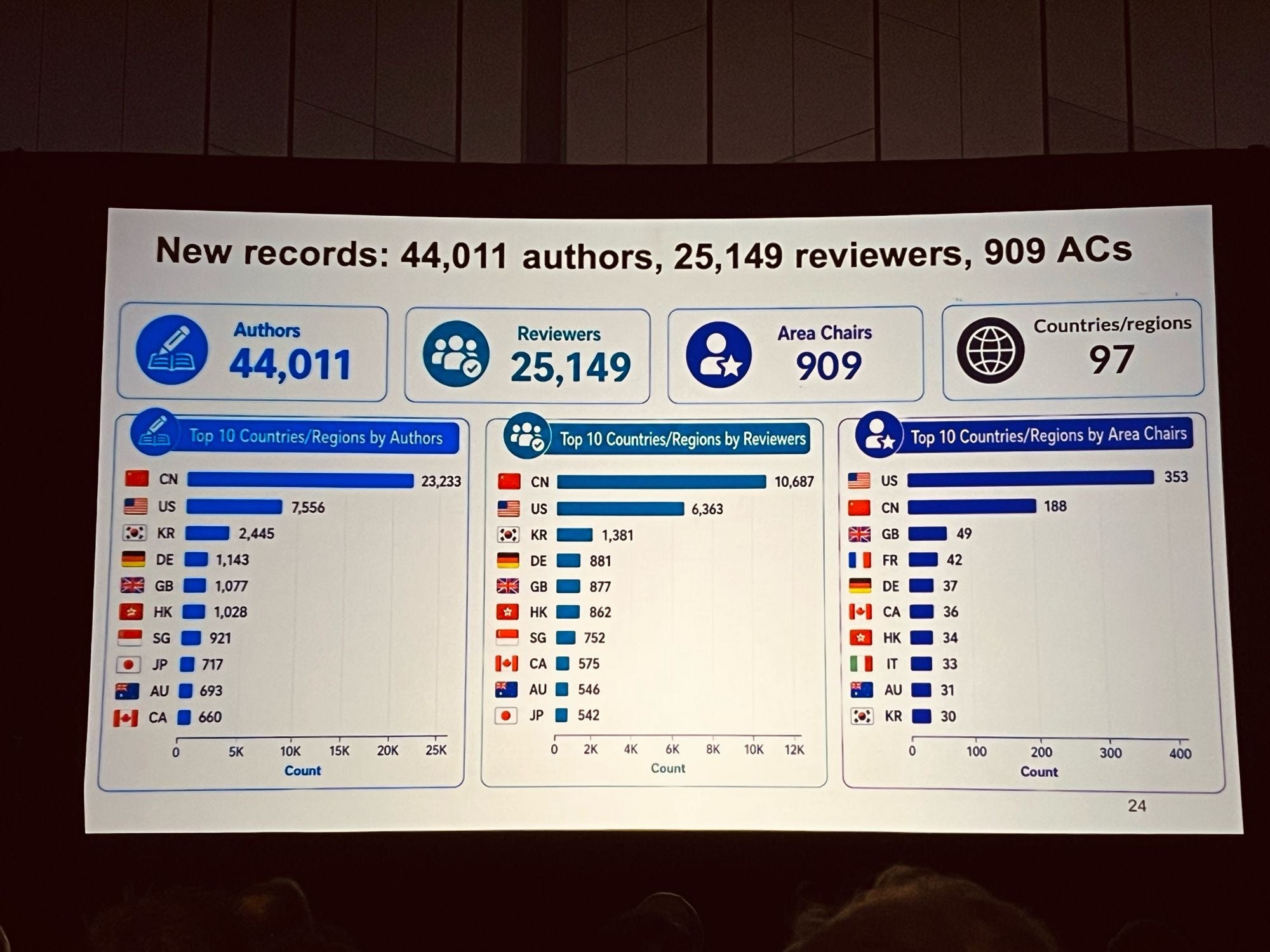
Chinese research is now the center of gravity at CVPR, while Chinese researchers are increasingly missing from it. This year’s numbers set new records — 44,011 authors and 25,149 reviewers across 97 countries — and China dominated both: 23,233 authors from mainland China alone, more than half the total and three times the US count of 7,556. The reviewer pool tells the same story: 10,687 from China against 6,363 from the US.
However, the immigration challenge kept many Chinese first authors home, producing an awkward situation — a second author delivering the oral by reading a script, then standing helpless through Q&A on work they didn’t know much about. The poster sessions felt noticeably emptier than in past years. The student from my inbox was one of many. On the second morning, I pinned his poster to its assigned board, photographed his first internationally accepted work, and sent the picture to him over WeChat. His visa was rejected largely because his university is one of China’s “Seven Sons of National Defense,” a group of institutions that has become a near-automatic red flag in US visa screening.

( photo of an attendee chcking out my student’s poster)
Against that backdrop, Chinese scholars did enjoy a feel-good underdog moment this year: an honorary mention for a paper by a group of undergraduates from Guangdong University of Technology, a school most people had never heard of. No PhD advisors. Ancient Titan GPUs. The running joke online: their real advisor was ChatGPT.

( image from @CVPR)
Jokes aside, something interesting is here: AI tools are dismantling one of research's oldest gatekeepers — the English language. A friend who reviews academic papers at these conferences has admitted, off the record, that papers sometimes get rejected not because the ideas are bad but because the prose is impenetrable. LLM translation is changing the game: if one's thinking is clear in their own language, they can now write clearly in any language. In a field where the majority of authors now think in Chinese first, that's a liberating thought.
Benchmarks: we would all be better off with more openness

( image from @CVPR)
This year’s best paper came from Google DeepMind (with University College London and Oxford collaborators), and the award committee praised it for elegantly unifying depth estimation, camera pose, 3D point tracking, and 4D point clouds. The criticism, nonetheless, followed almost immediately: no code, no public API, private datasets, and too little detail to reproduce.
That has pushed an open argument about the rules: should awards require releasing something the community can build on? One proposal that many seem to like is benchmarks with weight classes. Stop comparing papers on raw performance and start comparing within compute brackets, the way boxing separates heavyweights from featherweights. Your 10-GPU result competes against other 10-GPU results. It wouldn’t fix the closed-artifact problem, but it would let academia compete on cleverness rather than capex.
Networking: a big tech workers’ summer camp
Honestly, the best thing about CVPR is the community — being in the same building as people who are normally too busy to exist, and having the spontaneous hallway conversations that no amount of cold emailing can produce. CVPR feels like a big field party for tech talent, a once-a-year migration where everyone shows up.

( image from @CVPR)
The field now has genuine fan culture, too. Computer vision has celebrities, and some researchers carry near-idol status — I watched Dr. Kaiming He get stopped for photos more than once, and big names like Alyosha Efros were booked into speaking slots several times over in the same week.
And the media — my own tribe — loves a good story. Within days, the undergrad paper became instant content for three major Chinese tech WeChat accounts (量子位, 机器之心, 新智元), and the race to land the first interview with the first author was on. But almost all of the coverage stops at the viral underdog narrative; very little engages with the substance of the work itself. Part of why I’m writing this post is to keep some of the nuance on the record.
See you next year in Seattle, CVPR.
Such a delightful and timely field note! 🤩